

Overview: This report provides a high-level overview of how Photon Insights tackles the problem of sentiment analysis. “Photon Insights” (i.e., surfaced relevant insights and information for business, commerce and finance) from a myriad of topics are randomly selected, and performance of proprietary Photon Insights AI-based Sentiment Analysis Engine is compared to state-of-the-art open-source models.
In this analysis, we focus on two content segments, “regular” topics (with a slight skew towards finance) and “tricky” topics such as inflation, gas prices, recession, bonds, interest rates, yield curve, etc., for which state-of-the-art models (SOTA) perform very poorly (where there is some ambiguity as to whether rates dropping/rising is good or bad). In this paper, we provide a high-level overview of our AI-based Photon Sentiment Engine, and its performance relative to SOTA models (for both “regular” and “tricky” topics) plus we propose avenues of improvement. Our proprietary Photon-BERT alone heavily outperforms the top open-source models available on huggingface for both sets of topic groupings.
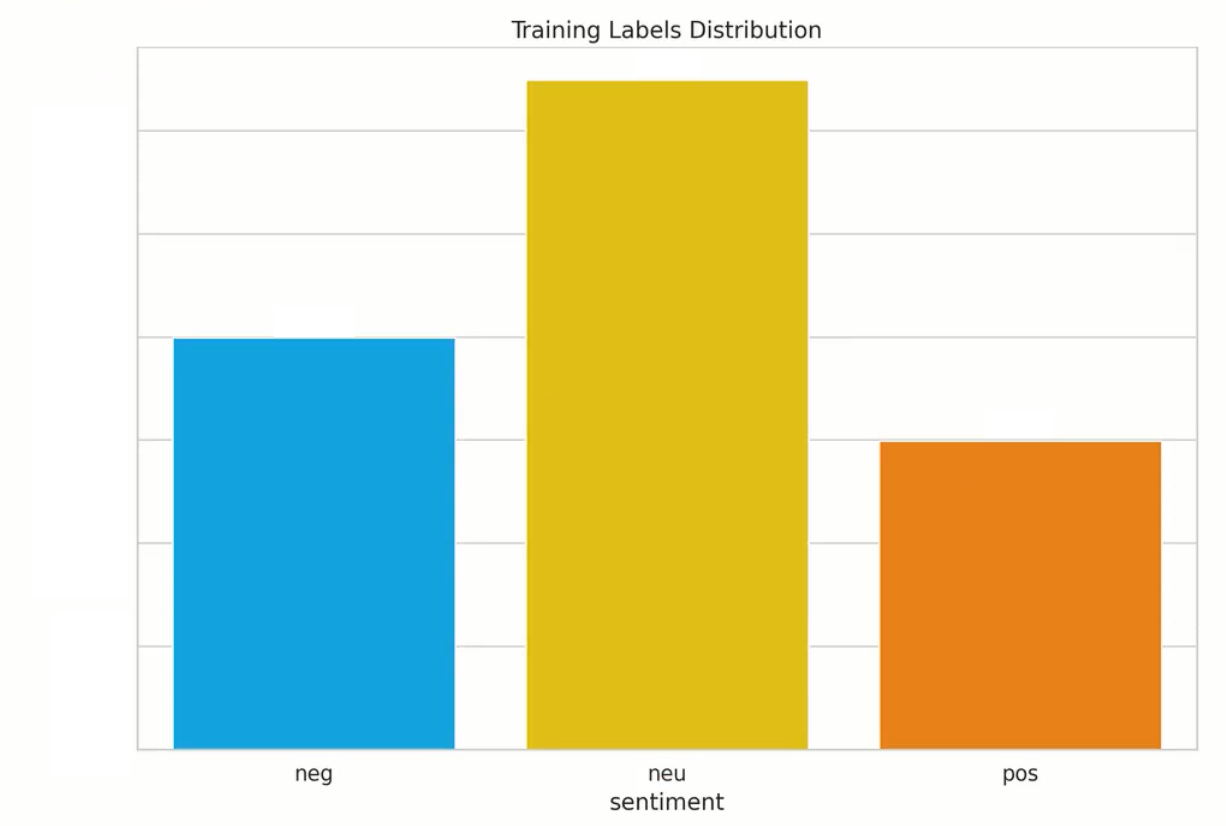
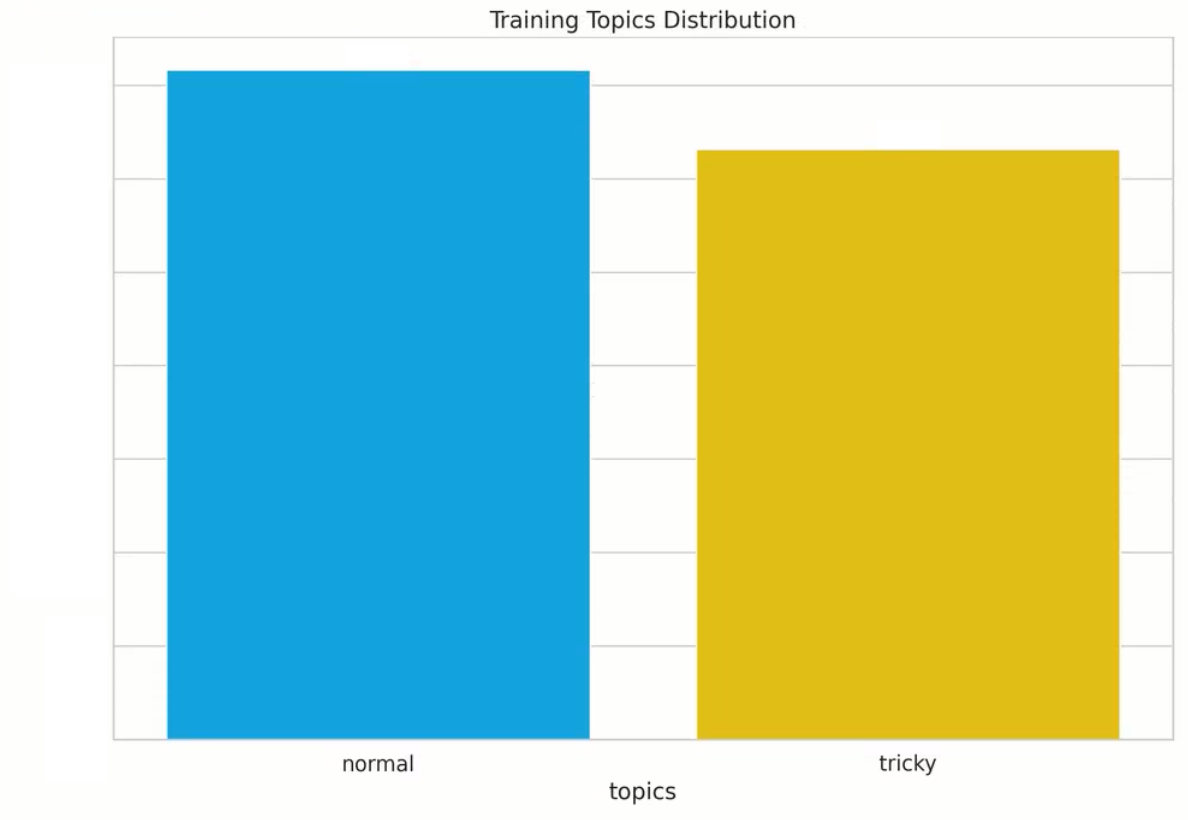
Background: We manually annotated a proprietary large dataset for the purpose of this case study. 80% of these samples were used during training and parameter optimization, and 20% were put aside as a golden test set for the final evaluation (our production architectures are trained on a more sizable dataset which we continue to augment via user feedback). We had two sets of annotations: general + topic-based (which are naturally subject to possible human error and variation, as is the case with all manually annotated datasets). In this analysis, we focus on the general sentiment. Below are histogram plots of the sentiment labels and topic distributions of our proprietary dataset (where tricky topics include recession, inflation, US inflation, yield curve, oil prices, gas prices, and general include all others – also note, we had several dual labels, i.e., neg,neu (negative, neutral), for the purpose of these plots/to keep the number of classes as 3, we displayed them as neu (neutral), but when evaluating our models, either prediction was deemed correct).
Train:
Test:
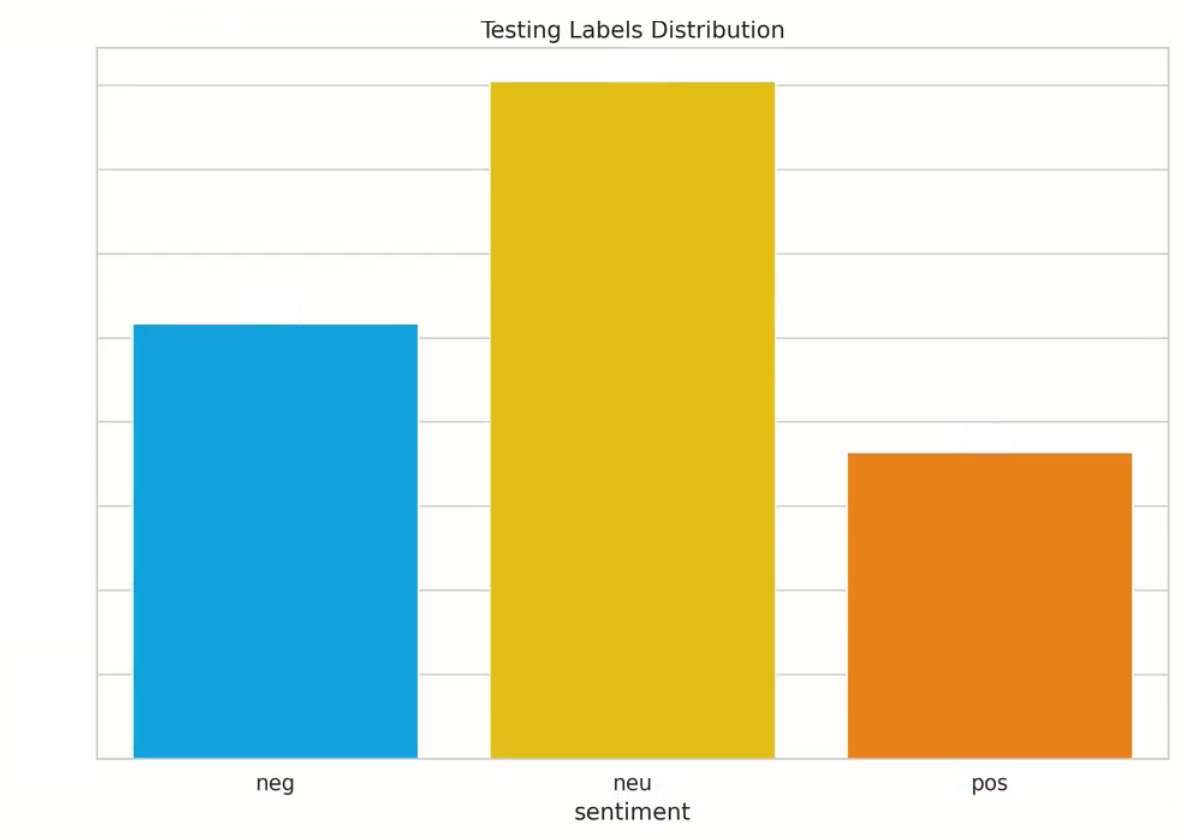
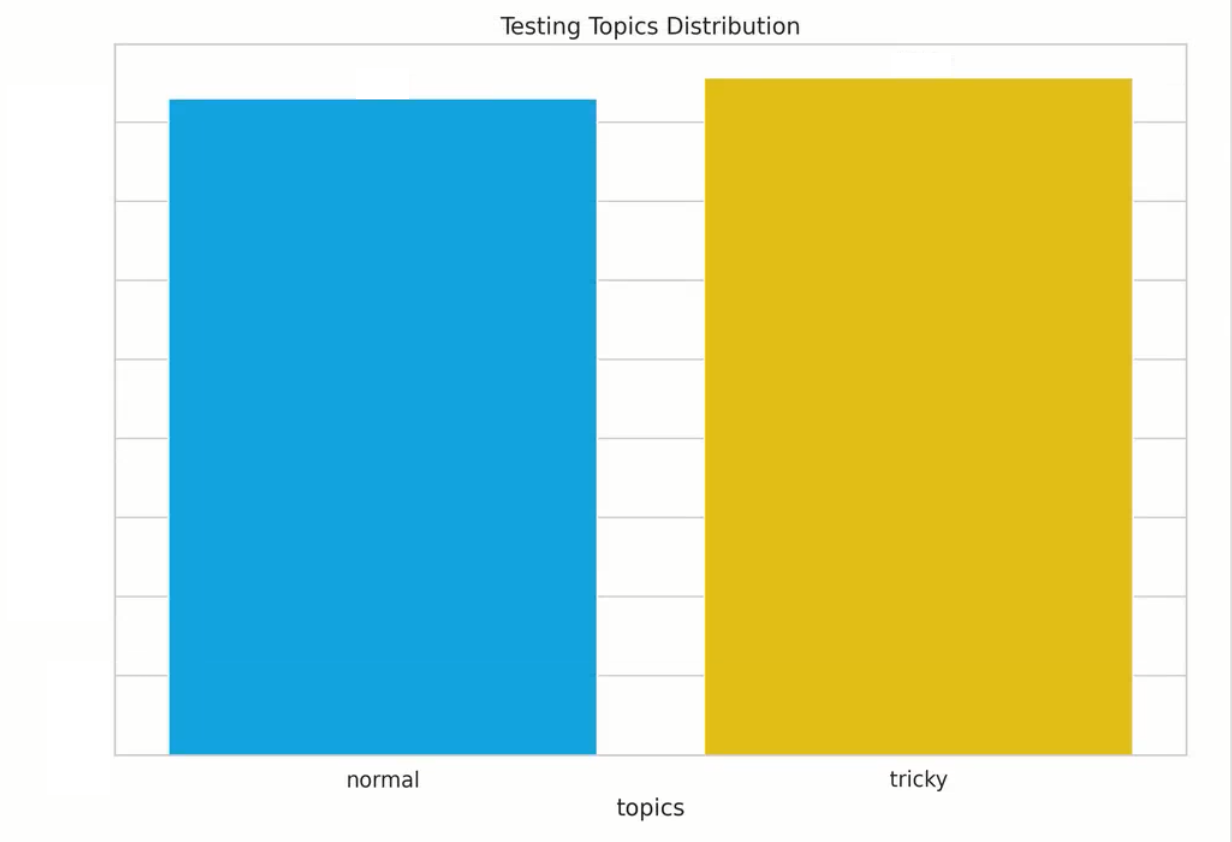
Photon Sentiment Engine: below is a performance breakdown of our proprietary model, and how it compares with other state-of-the-art open-source large-language models on the test set (broken down by category, “normal” vs. “tricky”).
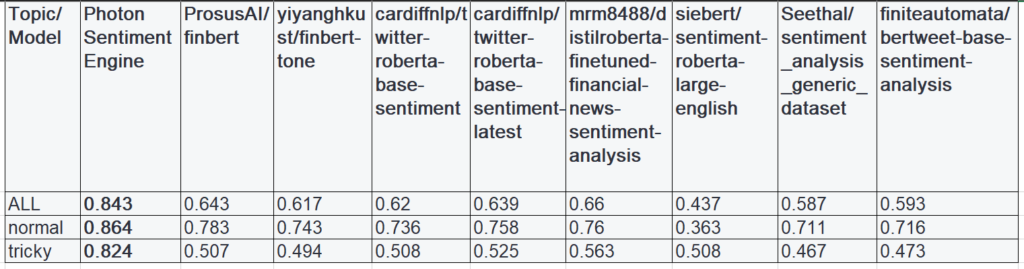
Confusion matrices for Photon Sentiment Engine: The following confusion matrices depicts the percentage of the data points in that particular topic group. One could argue the most egregious errors are predicting true negatives as positives, and true positives as negatives – with our architecture, we only predicted 3.52% negatives as positives, and 4.25% positives as negatives. We provide similar breakdowns for tricky topics vs. regular topics – which we were satisfied with given the complexity of the task (note the majority of egregious errors was derived from tricky topics, but the overall performance was still strong relative to SOTA open source models, even for tricky cases).
ALL TOPICS: Regular Topics: Tricky Topics:
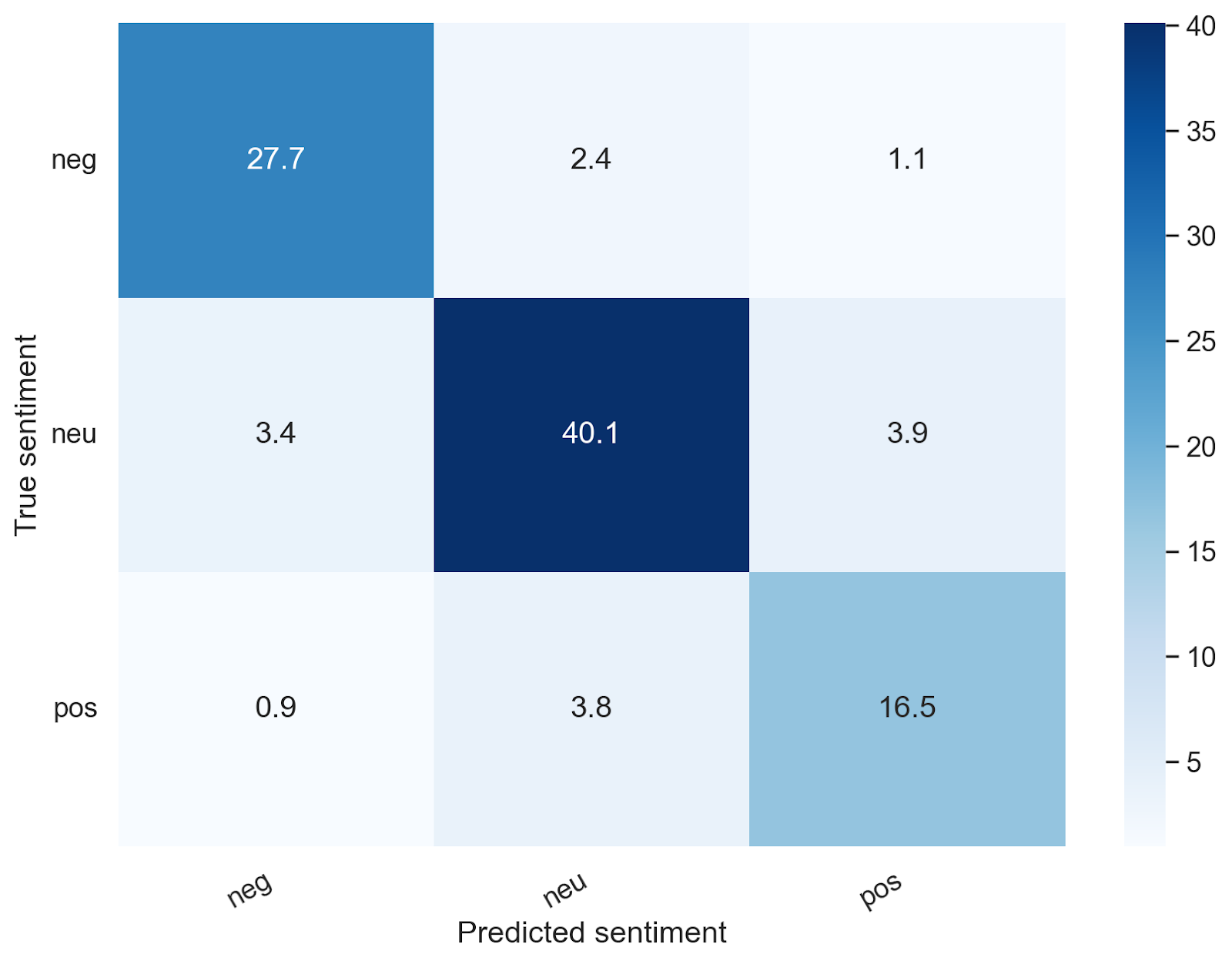
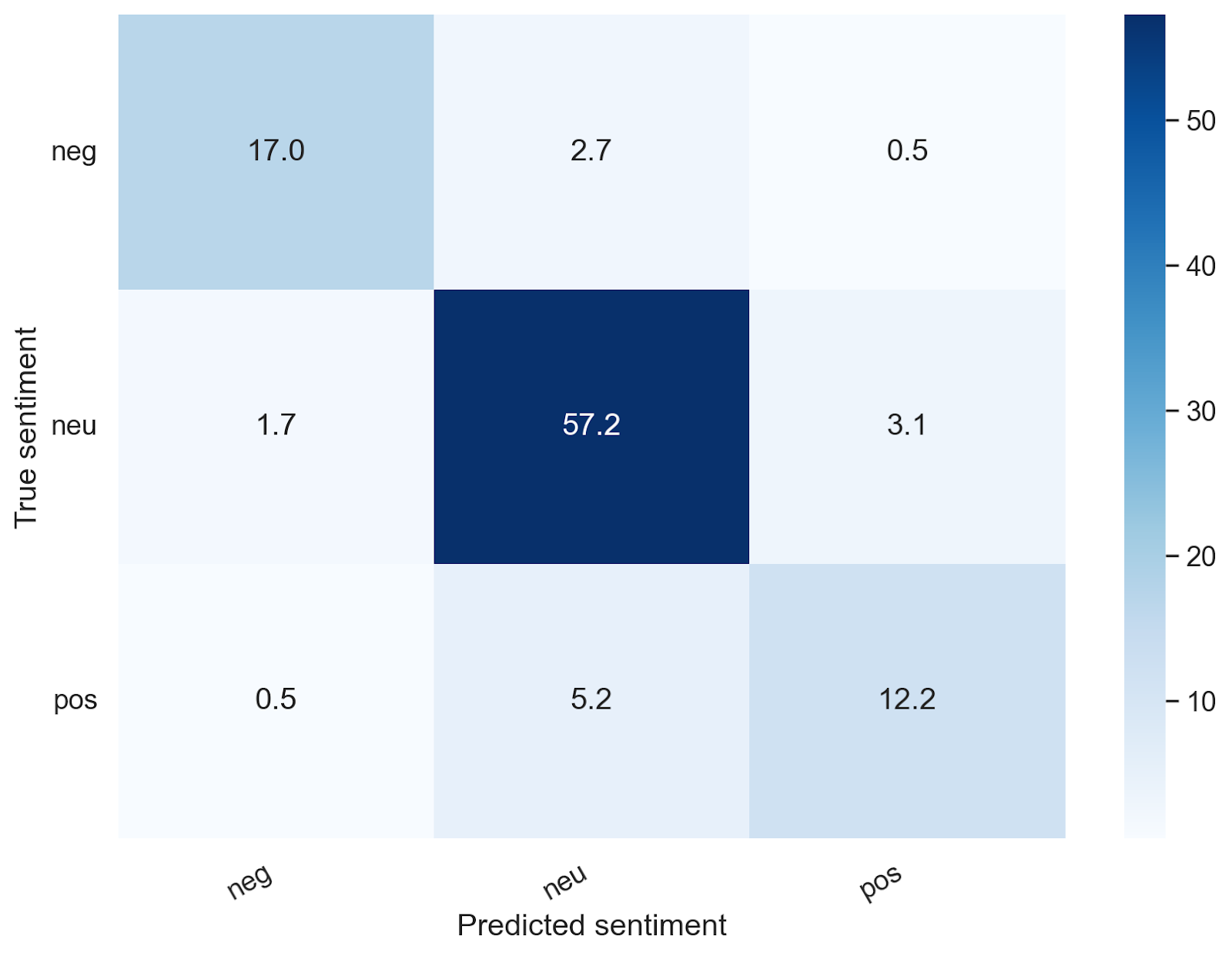
The numbers represent the percentages with respect to that particular topic group
The Photon Sentiment Engine understands nuance beyond basic financial large language models (LLMs), and by the inherent nature of sentiment, there is ambiguity, but at least with respect to blatantly positive and negative, our algorithms generally do not tend to label positive happenings as negative and vice versa, as seen above.
Here are a few of the tricky mistakes we hope to avoid in the future/current limitations of our model – some of these can be resolved by aspect-specific analysis as well, and we included a few examples which illustrate some of the difficulties in labeling:
| Predicted as negative, actually positive | Predicted as positive, actually negative |
| Bank of Israel figures show value of mortgages in Israel continues to fall.[Highly subjective/aspect based?] | Increase was above all economists’ forecasts in a Reuters poll. [Needed more context, relative to inflation] |
| Treasury yields rise as economic data suggests the economy is softening.[Highly subjective/aspect based?] | The flu season is off to a strong start in Pennsylvania and the nation. |
| The company’s PE ratio and other metrics suggest it is undervalued. | Bond prices are falling because inflation keeps surprising to the upside, in our view, leading investors to continually raise their expectations of the amount by which the federal reserve will have to raise interest rates.[Very tricky] |
| Experimental therapeutic cancer vaccine led to significant tumor regression in mice.[Outside the general domain of our algos] | Oil prices have recovered in the past month.[Very tricky, prices recovering for oil/gas bad] |
| Saudi energy company Aramco credits higher crude oil prices and higher refining margins for the jump.[Aspect-based, higher crude prices] | Housing prices are falling for the first time in years and investors are worried about inflation.[Highly subjective/aspect based?] |
Also, it should be noted that some sentences could have completely different sentiments to different readers, different market segments depending on their point of view, business market sector or interests. For the future, we are also envisioning a more fine-grained personalization option for a higher tier product offering to realize an enhanced customer experience with extra added value.
Conclusions:
The Photon AI-based Sentiment Engine significantly outperforms the SOTA open-source models on hugging-face. Due to the nature and subjectivity of sentiment analysis, it is difficult to organically obtain exceedingly high accuracies (i.e. we could say achieve a 95% plus accuracy if we trained on the financial phrasebank, but not on our randomly sampled dataset of Photon Insights/summaries generated from a list of common plus tricky topics), but what we plan to add to enhance our user experience is
1. Aspect-based sentiment analysis (i.e., sentiments corresponding to specific subjects in phrases)
2. User-specific sentiment analysis (i.e., learn what user preferences are, i.e., an investment banker might actually prefer rising interest rates, and display sentiments accordingly, eventually as granular as a per-user basis).



